
The new fintech stack is... open source?
Why open source is a powerful strategy — how to determine where open source is most and least effective — where open source is best suited in fintech

This piece was co-written with Patrick Malatack, former GM & VP Product at Twilio and now a partner at Matrix, where he focuses on developer tools and infrastructure.
A growing number of fintechs rely on stars. Not movie stars or sports stars. Thanks to the increasing popularity of open source in fintech, these are Github Stars. It’s worth understanding why this is happening and what it means for the industry. But before getting to fintech, let’s recap the open source model and the lessons from the last several decades.
The closed-source model is more typical in software. It means the company’s source code is proprietary and not shared publicly. It’s often monetized directly through licenses or subscriptions.
The open-source model takes the opposite approach: the source code is publicly available. Anyone can see, fork, modify, and run it on their own. There may be some limits on how the code can be used, but generally, anyone is free to do what they want with it.
While some open-source projects are explicitly not-for-profit, others have built large and successful for-profit companies around an open-source product. In this case, a company makes the core product (or at least its source code) freely available, then monetizes products and services adjacent to it, such as:
Cloud hosting: a hosted version of the software through a traditional SaaS model for companies that don’t want to deal with setting up and maintaining the source code themselves.
Enterprise management: a non-open source enterprise offering with additional management features and capabilities.
Services & support: services relevant to a company that is implementing the software, such as implementation support and ongoing support.
For example, the popular open-source company MongoDB allows anyone to copy, customize, and use their code for free. But this means they’d have to set up their own hosting, figure out how best to implement it, and continue to maintain it. On the other hand, they could pay MongoDB to use Atlas, their fully managed cloud service. And in fact, 64 of Fortune 100 companies, along with 40,000+ other companies prefer to do this. As of mid-2023, they had more than 1,600 companies paying more than $100,000 annually for this otherwise “free” product.

Why even bother with open source? It’s certainly not a fit for every product and category. But in certain cases, it offers significant advantages:
distribution and adoption: especially in crowded markets, it can increase adoption and usage faster than a closed-source model. Developers will play with and use the open-source version, and some will eventually pay some other way (more on this below). This is not that dissimilar from the freemium playbook.
transparency and trust: since anyone can see the code, anyone can understand how it works and ensure it does nothing nefarious. Similarly, since the code can be self-hosted, users can feel safe knowing that even if the company goes out of business, they can continue using the software.
So open source is a powerful strategy, but it’s not equally powerful in all categories. The history of open source offers many lessons on where and how it’s best applied.
Where open source does and doesn’t work
The modern computing stack (app, platform, infra) contains multiple examples of open- and closed-source products in many areas (such as web browsers, operating systems, web servers, etc.).

While the open/closed source dichotomy dates to the early days of computing in the 1950s and 1960s, its modern and more commercial form arose in the 1980s and hit its stride in the 1990s. While companies like Microsoft popularized closed-source versions of products like operating systems, databases, web servers, and programming languages, others like Red Hat, MySQL, Apache, and Sun Microsystems built businesses around open-source products in each of those categories.
Billions of users today use open and closed-source products, whether they know it or not. This includes products like web browsers (Firefox is open source, Safari is closed, Chrome is a mix) and mobile operating systems (Android is open source, iOS is closed), as well as entire companies built on the open-source model.
So, after decades of investment and development, the market has given some indications of where open source works well (or not). To understand those implications, you need the concept of a category’s “connectedness”, or how reliant a product is on third-party commercial arrangements to deliver value. A good rule of thumb here is: if a product could run entirely within a computer or company and still be valuable without significant reliance on third parties to deliver value, then it has low connectedness. The more it relies on third parties to deliver value, the more connected it is.
For example, a database has a very low degree of connectedness, because it can be run inside a company. Typically all the data is generated, read, and modified from within the company itself. On the other hand, a communications orchestration platform, such as Twilio, has high connectedness. It relies on a patchwork of global telecom deals to function and deliver value. Other categories are somewhere in the middle, where they may or may not benefit from significant connectedness.
Many (but not all) application categories have high connectedness, while most (but not all) platforms and infra categories have low connectedness.

Getting back to open source, the last few decades have shown that categories with less connectedness are more likely to be successful with open source. That doesn’t mean that categories with low connectedness will only be successful with open source, or that open source will necessarily be the most successful in those categories. Instead, it means that if open source is likely to be successful anywhere, it will be in those categories.

That’s because the connectedness requires a more concerted sales, marketing, growth, and/or business development effort than makes sense to organize around an open-source project. For example, for a connected service like Twilio to be valuable, it requires tons of business development deals with telecom carriers around the world. This highly connected product category is unlikely to be successful without these deals. The deals are a critical part of the product and the product is a critical part of the deals. Twilio’s software has minimal value without the deals, and the deals have minimal value without the software to orchestrate them. So a standalone open-source version of the product is unlikely to be valuable. On the other hand, in less connected product categories, like data systems, the products are more able to stand on their own and so are more likely to have some value as an open-source project from day one.
The financial services stack
The financial services stack is not that dissimilar from the computing stack. It’s an imperfect analogy, but financial services also have things analogous to applications, platforms, and infrastructure. You can think of applications as individual financial products and their user-facing components (e.g., P2P payments, checking accounts, budgeting tools), platforms as the foundation on which applications are built (e.g., banking-as-a-service providers, payment networks, account aggregators), and infrastructure as the more generalizable resources that enable the platforms (e.g., payment rails, risk engines, billing engines, etc).

Where to find open source in financial services
Like in the computing stack, financial product categories have varying degrees of connectedness. If anything, financial products are generally more connected than not because financial services often require interacting with third parties to deliver value. A P2P payment app isn’t valuable if you’re the only user on it. A banking-as-a-service vendor isn’t valuable if it’s not connected to any sponsor banks. A payment rail isn’t valuable if it has limited on- and off-ramps with other financial systems.
So, the financial services stack is becoming less monolithic, more modular, and more developer-led. That means more open source is popping up across the stack, just like in the computing stack in the 1990s. However, just as in that case, there are likely parts of the stack where open source will be more successful. Thankfully, there are decades of precedent from the developer world to suggest where that will be.
Like in developer tools, the opportunities are heavily weighted towards the less connected infrastructure side.
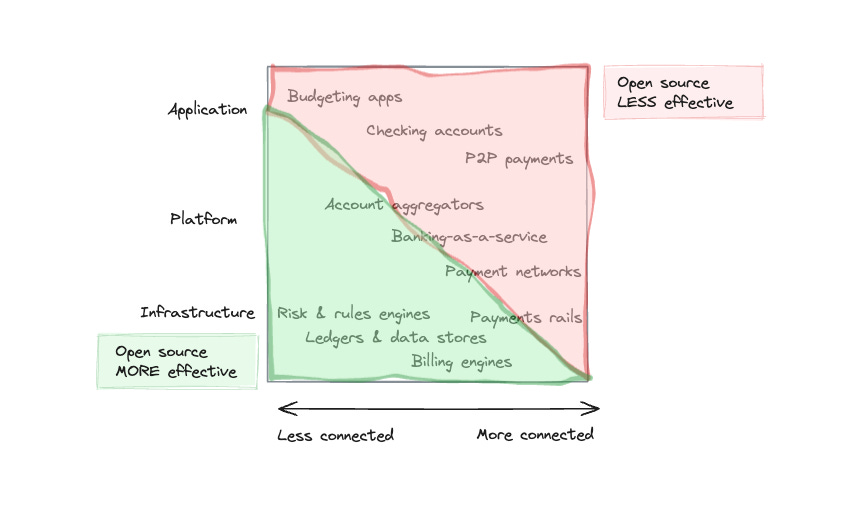
It’s unsurprising that many of the recent fintech players adopting open source are typically both infrastructure and less connected. You’ll find examples in risk and rules engines (Ballerine), ledgers and data stores (TigerBeetle), payments orchestration (Hyperswitch), loan management systems (Corefin), and billing engines (Lago). Understandably, there are fewer instances of the open source strategy further up the stack, but there are some, like Maybe.
It’s still the early days of software eating financial services. So it’s likely the early days of the open source model in fintech also. Hopefully the framework above helps founders decide whether or not open source is the right fit for their product category. Since it’s still early days, the market and model are changing often. Feedback is welcome on this framework… where does or doesn’t it apply to financial services? What product categories are more or less connected than they first appear? Where is open source really taking root in financial services?